Self-Distilled Reasoner: On-Policy Self-Distillation
As intelligence scales, learning need not rely solely on external supervision; sufficiently capable systems can refine themselves by reflecting on outcomes.
Much like a student reviewing solutions, rationalizing them, and correcting prior mistakes, an LLM can be conditioned on privileged info (e.g., correct solution or a reasoning trace) and supervise its weaker self—the version without such access—by matching the privileged-info-induced distribution from itself.
The Challenge of Current LLM Training Paradigms
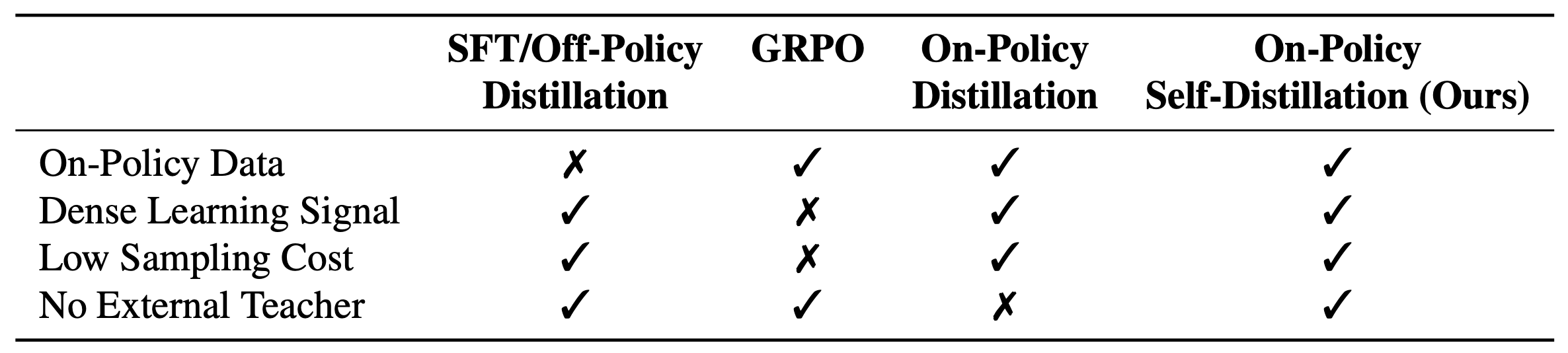
LLMs have shown impressive abilities in reasoning tasks, but finding more efficient and effective ways to train them remains an active area of research. Current popular approaches come with their own trade-offs:
Supervised Fine-Tuning (SFT) uses expert demonstrations for training but might encounter exposure bias
Reinforcement Learning (RL) methods, such as Group Relative Policy Optimization (GRPO)
Knowledge Distillation traditionally provides dense token-level supervision from a teacher model but relies on off-policy data
Core Insight
Given that modern LLMs already exhibit strong reasoning capabilities, we ask this research question: Can a model effectively serve as its own teacher through self-distillation? Specifically, when provided with ground-truth solutions as privileged information, can a sufficiently capable model rationalize the reasoning steps and provide dense token-level supervision to guide its weaker self—the version without access to privileged information?
Our approach draws inspiration from human learning. When students struggle with a problem, rather than relying on extended trial-and-error, they can examine the correct solution, understand the reasoning steps, and identify where their own reasoning went wrong. Prior work has shown that for LLMs, evaluation is often easier than generation
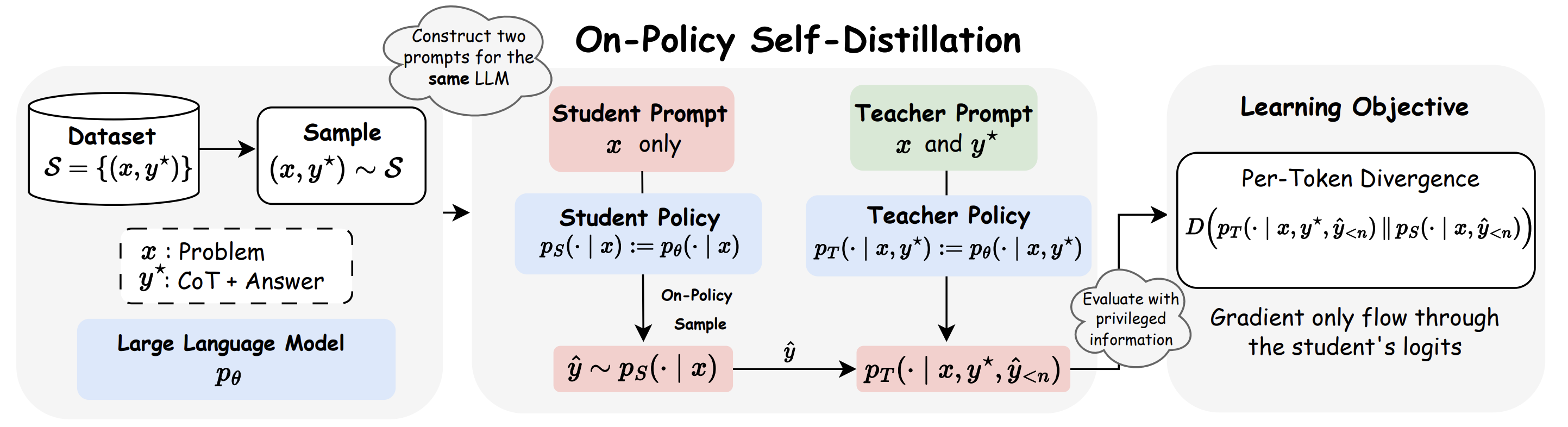
We show that the answer is yes through proposing On-Policy Self-Distillation (OPSD), where a single model plays two roles:
- Student policy \(p_S(\cdot \mid x)\): observes only the problem \(x\), replicating inference-time conditions
- Teacher policy \(p_T(\cdot \mid x, y^*)\): receives privileged access to the ground-truth solution \(y^*\)
Critically, both policies share the same parameters but differ in conditioning contexts.
Methodology
The training procedure consists of three steps:
1. On-Policy Sampling from the Student. For a given problem \(x\), the student policy samples its own attempted solution:
\[\hat{y} = (\hat{y}_1,\ldots,\hat{y}_{|\hat{y}|}) \sim p_S(\cdot \mid x)\]2. Teacher-Student Distribution Computation. Both policies evaluate the student’s generated trajectory \(\hat{y}\). At each token position \(n\), they compute probability distributions over the next token \(y_n \in \mathcal{V}\) conditioned on the same student prefix \(\hat{y}_{\lt n} = (\hat{y}_1,\ldots,\hat{y}_{n-1})\):
\[p_S(y_n \mid x, \hat{y}_{\lt n}), \qquad p_T(y_n \mid x, y^*, \hat{y}_{\lt n})\]The teacher policy, informed by the correct solution \(y^*\), provides guidance toward reasoning trajectories that lead to the correct answer.
3. Per-Token Distribution Matching. We instantiate a full-vocabulary divergence objective that matches the teacher and student next-token distributions at each position. We define the trajectory-averaged, token-wise divergence:
\[D(p_T \| p_S)(\hat{y} \mid x) = \frac{1}{|\hat{y}|} \sum_{n=1}^{|\hat{y}|} D\left(p_T(\cdot \mid x, y^*, \hat{y}_{\lt n}) \,\|\, p_S(\cdot \mid x, \hat{y}_{\lt n})\right)\]where \(D\) can be any distribution divergence measure such as the generalized Jensen-Shannon divergence \(\text{JSD}_\beta\), defined for a weight \(\beta \in [0, 1]\) as:
\[\text{JSD}_\beta(p_T \| p_S) = \beta D_{\text{KL}}(p_T \| m) + (1 - \beta) D_{\text{KL}}(p_S \| m)\]where \(m = \beta p_T + (1 - \beta) p_S\) is the interpolated mixture distribution. This full-vocabulary formulation provides dense, token-level feedback: the teacher, informed by \(y^*\), exposes the student to the entire distribution over plausible next tokens and guides it toward reasoning paths that lead to the correct answer.
We minimize the expected divergence between teacher and student over on-policy student samples:
\[\mathcal{L}(\theta) = \mathbb{E}_{(x,y^*)\sim \mathcal{S}} \left[ \mathbb{E}_{\hat{y}\sim p_S(\cdot|x)} \left[ D(p_T \| p_S)(\hat{y} \mid x) \right] \right]\]Gradients flow only through the student’s logits. The teacher serves as a fixed supervision target, despite both policies sharing the same underlying parameters but differing in their conditioning contexts.
Importantly, we fix the teacher policy to be the initial policy, rather than the currently updating learning policy, as we find this helps stabilize training and implicitly acts as regularization to prevent excessive deviation from the initial policy.
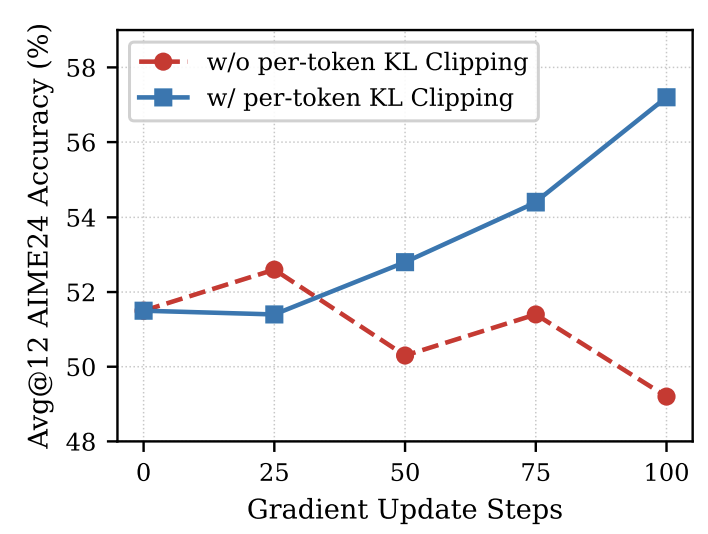
Per-Token Pointwise KL Clipping. In practice, we find that token-level divergence is highly skewed across vocabulary entries—a small subset of stylistic tokens (e.g., reasoning connectives like “wait”, “think”, “therefore”) exhibits much higher divergence than mathematically meaningful tokens. Without correction, these stylistic tokens dominate the training signal. We therefore apply per-token pointwise KL clipping, which caps the maximum per-vocabulary-entry divergence contribution at each position. We find this stabilizes training and prevents performance collapse, particularly important given that OPSD converges rapidly within a few hundred steps.

To situate OPSD among related approaches, we discuss the differentce between Self-Taught Reasoner (STaR)
Policy-Gradient Perspective
We can also view OPSD objective as a policy-gradient interpretation with a dense, token-level reward derived from privileged information. This framing also help clarify the difference between OPSD and STaR.
STaR as Sequence-Level Policy Gradient
First, STaR
STaR uses binary outcome filtering reward \(R(y) = \mathbf{1}(y = y^\star)\), the expected return is:
\[J_{\text{STaR}}(\theta) = \sum_{i=1}^N \mathbb{E}_{(r, y) \sim p_\theta(\cdot \mid x_i)} \big[ \mathbf{1}(y = y_i^\star) \big]\]Applying the log-derivative trick gives STaR’s gradient:
\[\nabla_\theta J_{\text{STaR}}(\theta) = \sum_{i=1}^N \mathbb{E}_{(r, y) \sim p_\theta(\cdot \mid x_i)} \Big[ \mathbf{1}(y = y_i^\star) \, \nabla_\theta \log p_\theta(r, y \mid x_i) \Big]\]The correct answer filtering discards the gradient for all sampled rationales that do not lead to the correct answer. STaR’s reward is sequence-level: the binary indicator assigns the same signal to every token in the trajectory, with no intermediate credit assignment.
OPSD as Dense-Reward Policy Gradient
We can also view the sampled-token objective in OPSD as a policy-gradient method, but with a token-level reward. For a training pair $(x, y^\star)$ and a student-generated trajectory $\hat{y} \sim p_S(\cdot \mid x)$, define the per-token reward at position $n$:
\[r_n(x, \hat{y}) \triangleq \log p_T(\hat{y}_n \mid x, y^\star, \hat{y}_{\lt n}) - \log p_S(\hat{y}_n \mid x, \hat{y}_{\lt n})\]This measures how much the privileged teacher prefers the sampled token relative to the student. Treating $r_n$ as a constant with respect to $\theta$ (stopping gradients through both $p_T$ and $p_S$ in the reward), the gradient takes the standard policy-gradient form:
\[\nabla_\theta \mathcal{L}(\theta) = -\mathbb{E}_{(x, y^\star) \sim \mathcal{S}} \left[ \mathbb{E}_{\hat{y} \sim p_S(\cdot \mid x)} \left[ \frac{1}{|\hat{y}|} \sum_{n=1}^{|\hat{y}|} r_n(x, \hat{y}) \, \nabla_\theta \log p_S(\hat{y}_n \mid x, \hat{y}_{\lt n}) \right] \right]\]This corresponds to maximizing the expected per-token reward along on-policy student rollouts:
\[J_{\text{OPSD}}(\theta) = \mathbb{E}_{(x, y^\star) \sim \mathcal{S}} \left[ \mathbb{E}_{\hat{y} \sim p_S(\cdot \mid x)} \left[ \frac{1}{|\hat{y}|} \sum_{n=1}^{|\hat{y}|} r_n(x, \hat{y}) \right] \right]\]Both STaR and OPSD can be viewed as policy-gradient methods, but differ in the nature of reward. STaR uses a sequence-level reward from outcome; and when incorrect reasonings are thrown away. OPSD provides a token-level reward at every position through rationalization on the privilledged info, and it can still learn even when the final answer is wrong.
Experimental Results
We evaluate whether OPSD’s dense supervision translates to practical gains on challenging benchmarks. We test on competition-level mathematical reasoning benchmarks using the Qwen3 model family. SFT, GRPO, and OPSD all used the same training datasets from OpenThoughts. For GRPO, we used a 16k generation length and sampled 8 rollouts per problem, while for OPSD, we used only a 1024 generation length for distillation and sampled only 1 rollout per problem. Our results show that OPSD is better than SFT and matches or exceeds GRPO while being significantly more token-efficient.
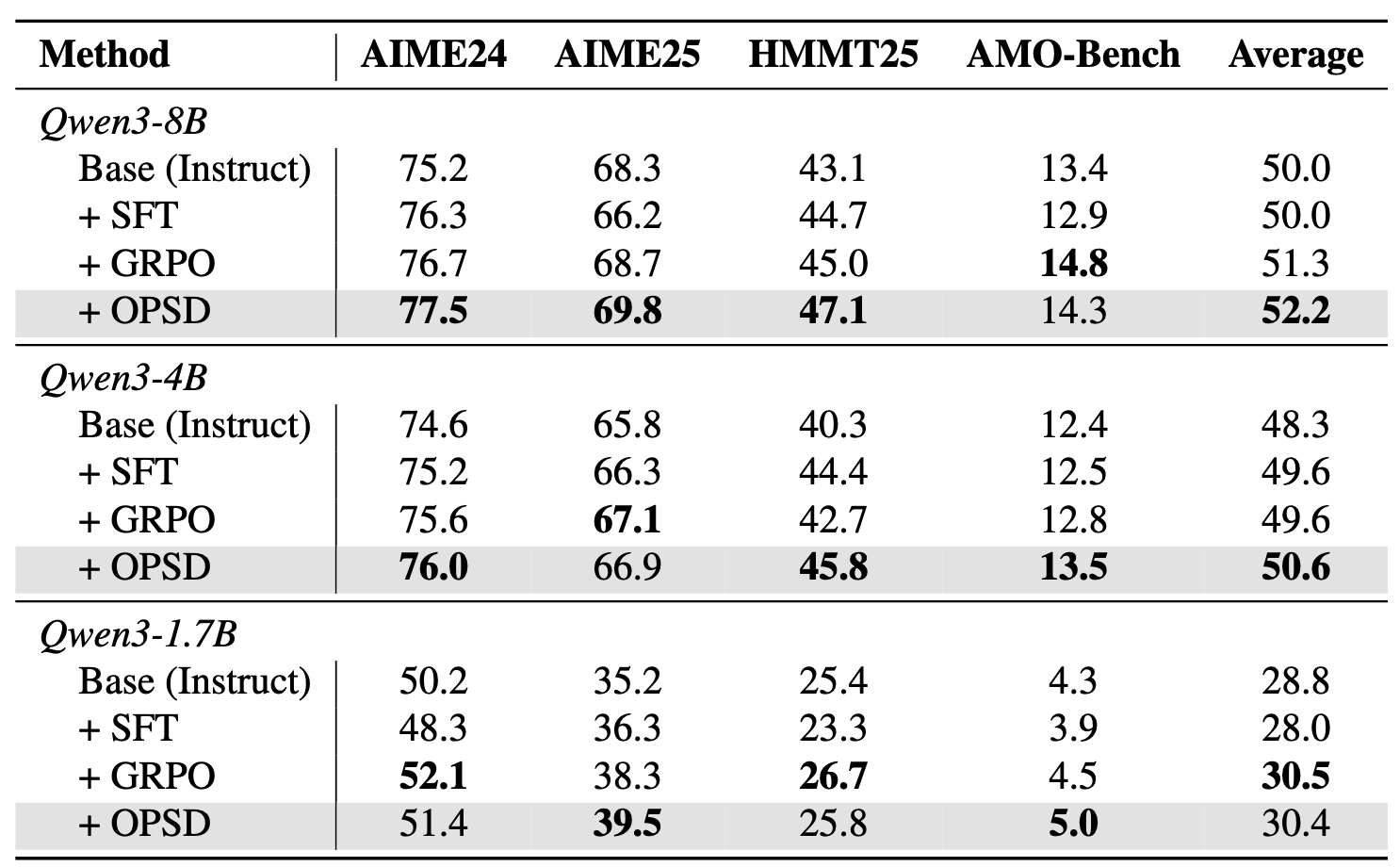
We observe SFT performance degrades because the concise reasoning solutions in OpenThoughts reduce generation length at test time; OPSD transforms these same concise solutions into dense token-level supervision through rationalization instead.
In the following figure we compare GRPO and OPSD performance within 100 steps. GRPO only receives a binary outcome reward, and stagnates due to reward diversity collapse (rightmost plot): more than half of its batches have zero reward standard deviation within 100 steps, yielding no gradient signal.
OPSD sidesteps this disadvantage of outcome-based rewards by learning from a dense distillation loss. OPSD could extract learning signal from the same reasoning datasets more efficiently than both GRPO and SFT when the reasoning datasets is too concise for SFT and difficulty level not suited for GRPO (with all-wrong/all-correct batches -> zero gradient).
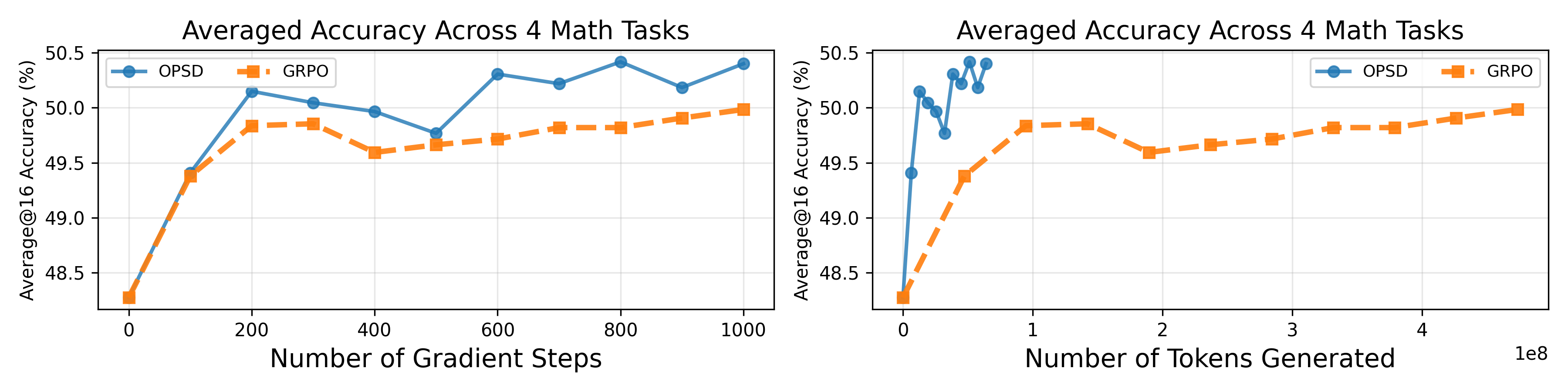
OPSD achieves competitive performance with only 1024 sampling tokens from the student. We hypothesize this is because early tokens are more important for distillation than later tokens—earlier tokens represent more critical branching points, while later tokens become more predictable to the teacher given a long enough student prefix, which is also noted in
Discussions
Effect of Student and Teacher’s Generation Style
A key design choice in OPSD is the generation style of the student and teacher models, as it determines both which tokens the student learns from and the style of supervision provided by the teacher. Qwen3 models support Thinking Mode on (TM-on), where the model produces chain-of-thought tokens, and Thinking Mode off (TM-off), where it responds directly. Among all four student/teacher pairings, the TM-off student paired with a TM-on teacher yields the largest KL divergence on math-related tokens, indicating stronger supervision on mathematically relevant content, and achieves the better downstream performance in our early experiments. Therefore we adopt this generation style in our experiments.
Effect of Per-Token Point-wise KL Clipping
Without clipping, stylistic tokens dominate the training signal and destabilize learning. As shown below, per-token pointwise KL clipping stabilizes training and prevents performance collapse — particularly important given that OPSD converges rapidly within a hundred steps.
Limitations and Future Directions
Verification signal integration & group self-distillation. The current OPSD framework does not explicitly incorporate correctness verification because we only generate 2-4k tokens from the student for distillation and they haven’t generated the EoS token. Combining distribution matching with outcome-based verification signals could provide better learning objectives. For example, one could sample a group of full responses, check correctness, and use the model’s own correct reasoning trace to self-distill its incorrect attempts. This would eliminate the reasoning dataset requirement and might be more in-distribution, as the correct reasoning traces are generated by the LLM itself.
Curriculum learning strategies. When problems exceed the model’s comprehension threshold, even the teacher policy cannot provide meaningful supervision when conditioned on the correct answer, because the teacher cannot understand the solution and thus cannot provide a meaningful supervision signal on the student’s response. Adaptive difficulty adjustment—gradually increasing problem complexity as the model improves—could enhance training effectiveness.
Citation
If you find this work useful, please consider citing:
@article{zhao2026self,
title={Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models},
author={Zhao, Siyan and Xie, Zhihui and Liu, Mengchen and Huang, Jing and Pang, Guan and Chen, Feiyu and Grover, Aditya},
journal={arXiv preprint arXiv:2601.18734},
year={2026}
}