Abstract
Many applications of large language models (LLMs), ranging from chatbots to creative writing, require nuanced subjective judgments that can differ significantly across different groups. Existing alignment algorithms can be expensive to align for each group, requiring prohibitive amounts of group-specific preference data and computation for real-world use cases.
We introduce Group Preference Optimization (GPO), an alignment framework that steers language models to preferences of individual groups in a few-shot manner. In GPO, we augment the base LLM with an independent transformer module trained to predict the preferences of a group for the LLM generations. For few-shot learning, we parameterize this module as an in-context autoregressive transformer and train it via meta-learning on several groups.
We empirically validate the efficacy of GPO through rigorous evaluations using LLMs with varied sizes on three human opinion adaptation tasks. These tasks involve adapting to the preferences of US demographic groups, global countries, and individual users. Our results demonstrate that GPO not only aligns models more accurately but also requires fewer group-specific preferences, and less training and inference computing resources, outperforming existing strategies such as in-context steering and fine-tuning methods.

Background
LLM may disproportionately over-represent some groups and under-represent others. Although guiding an LLM using prompts such as "Speak as xxx" can enhance its performance, this approach is limited and can sometimes lead to misrepresentation.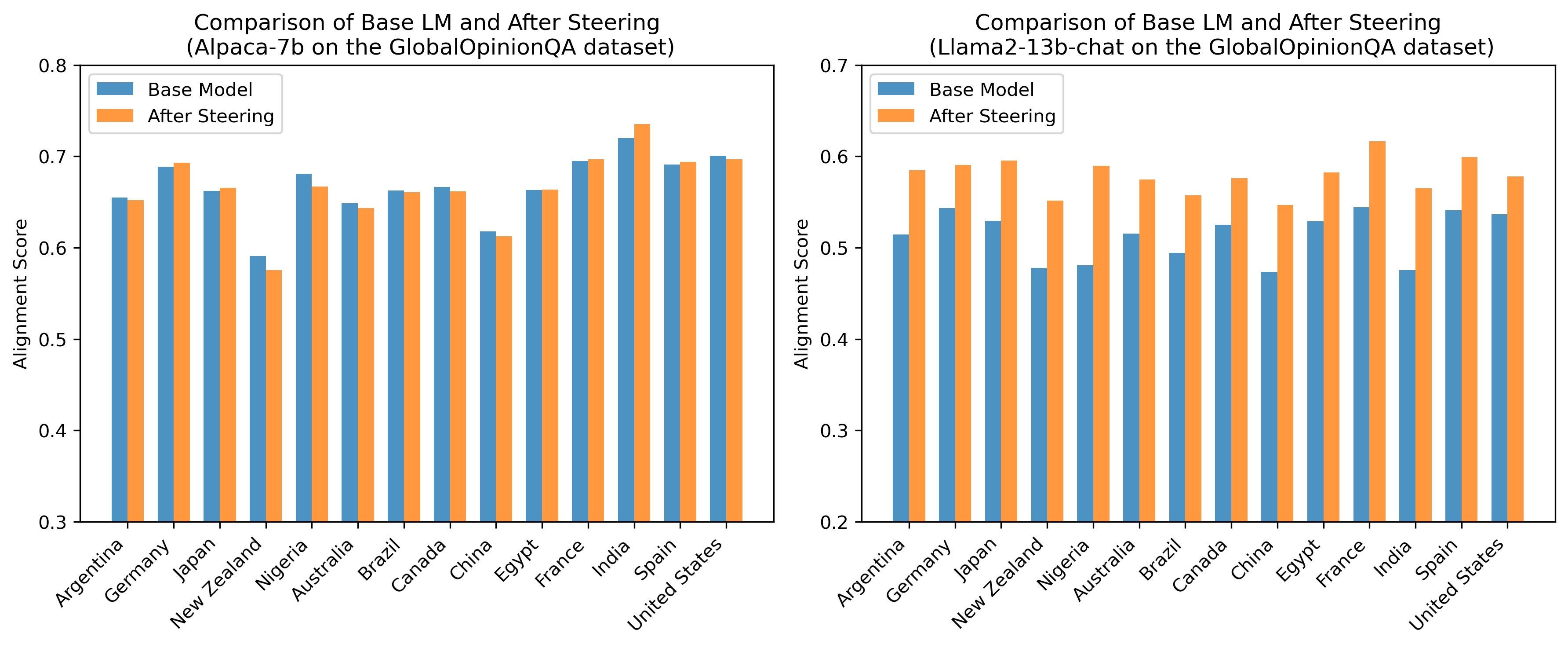
Method
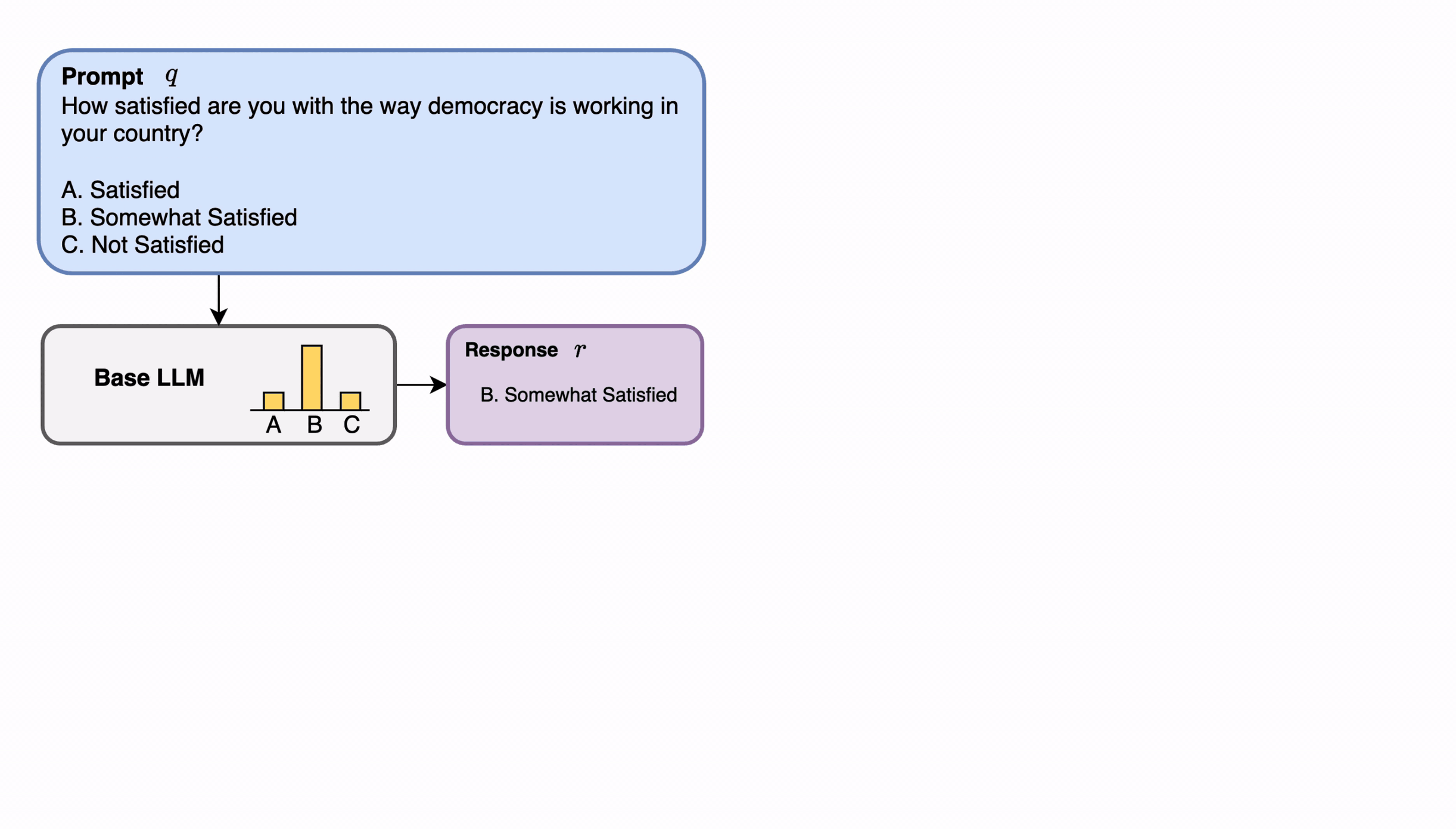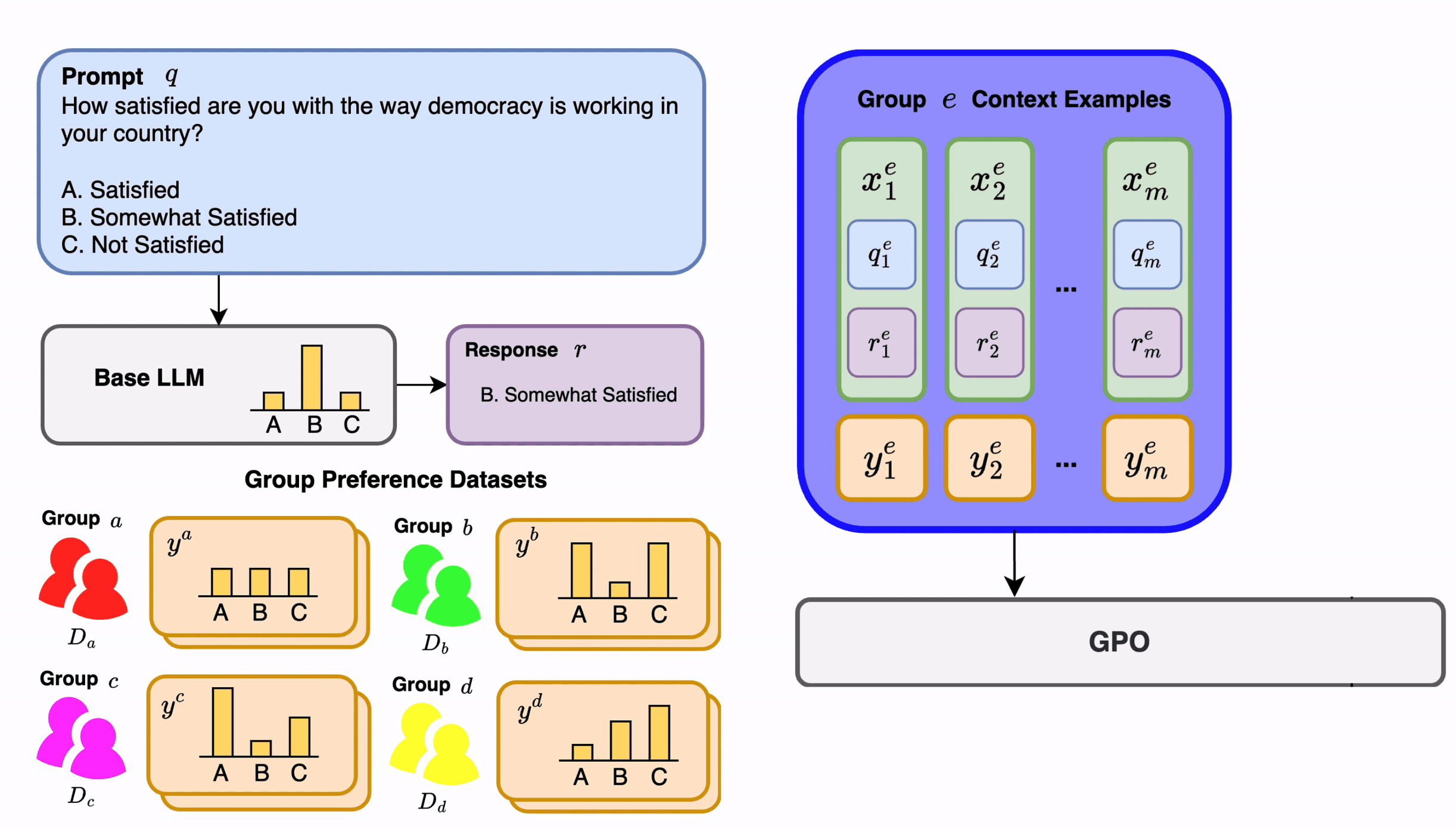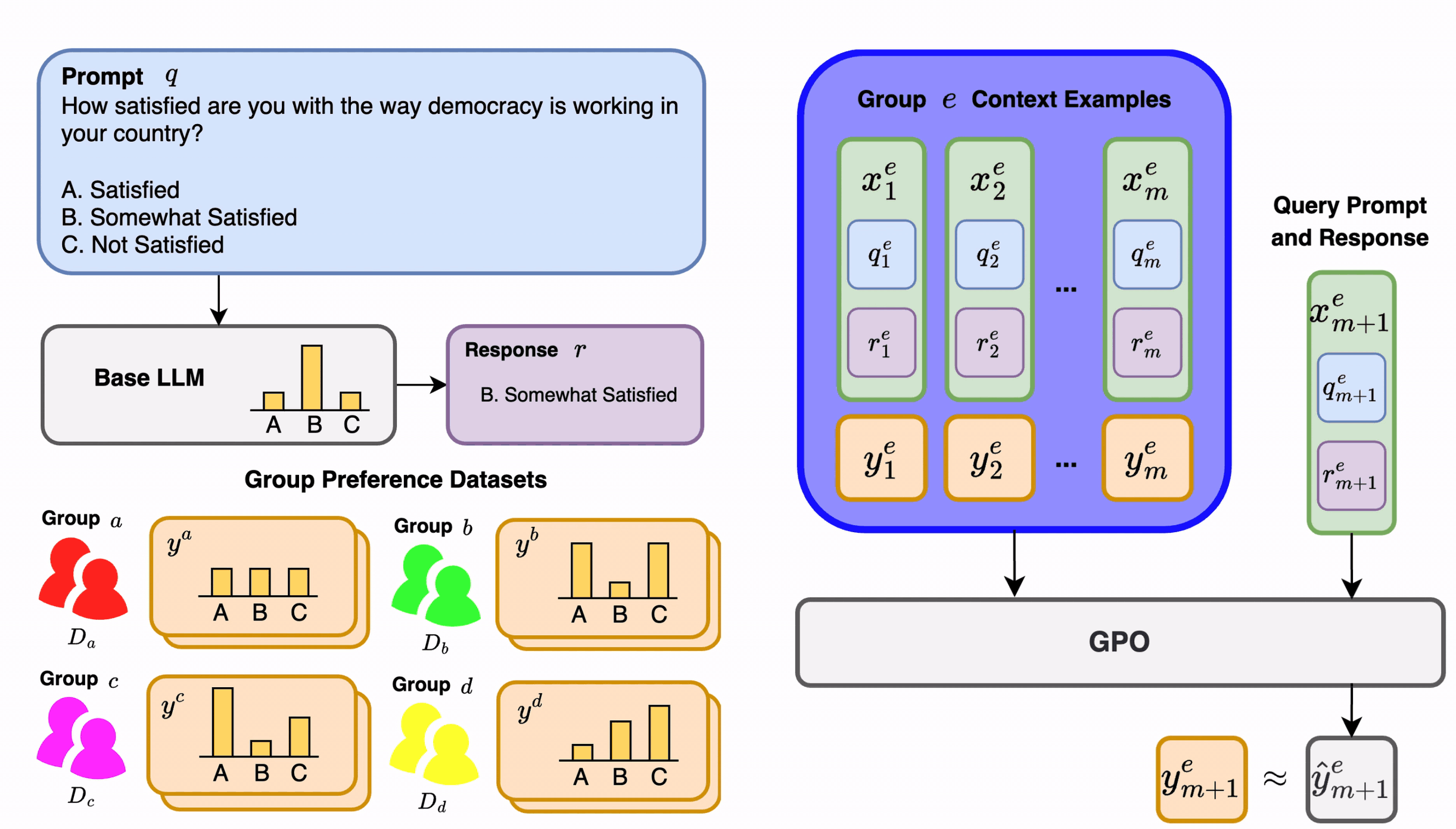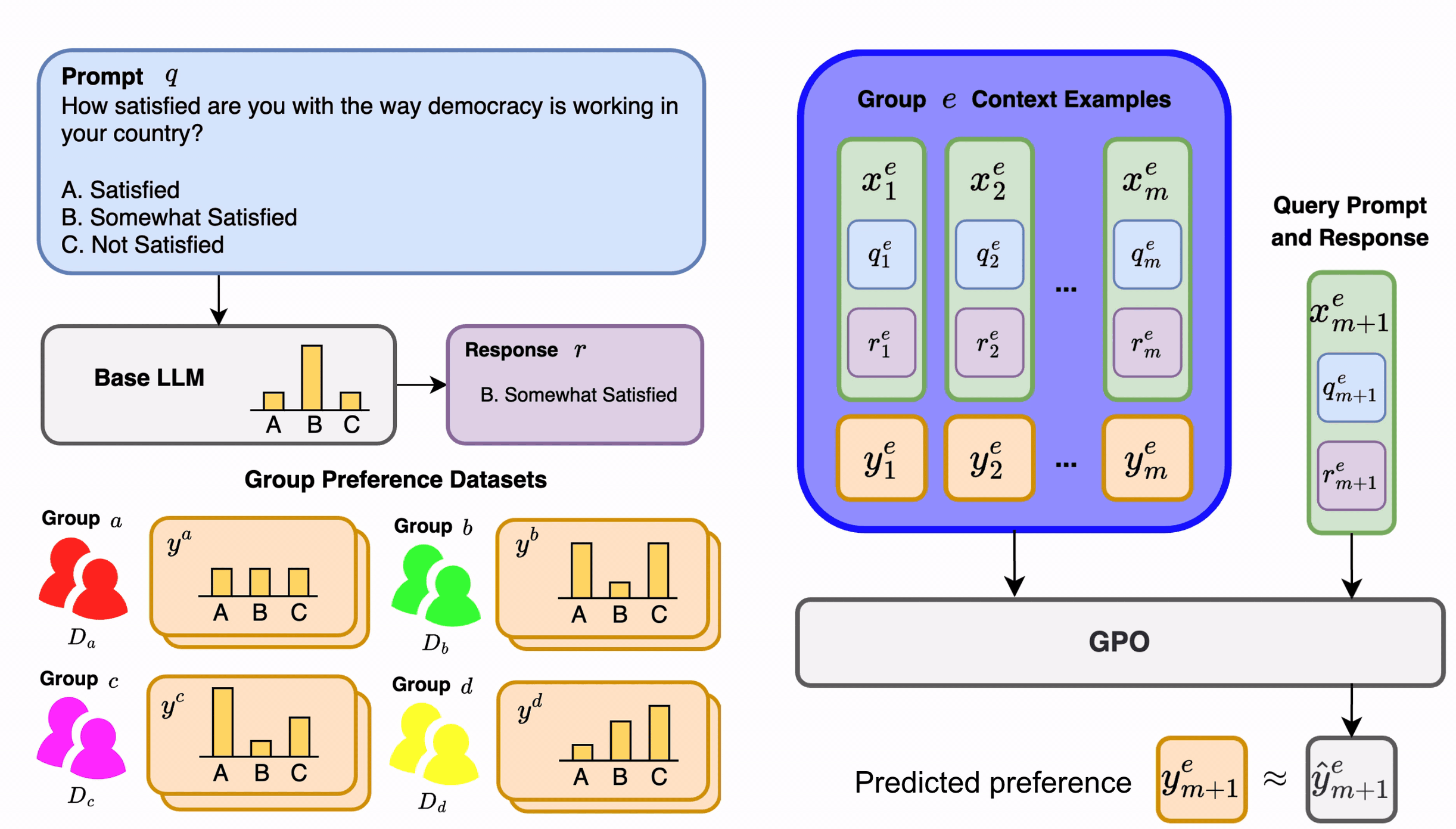
GPO performs few-shot supervised learning of human preference scores over LLM outputs. These predicted group preference scores can be utilized within downstream LLM alignment methods such as best-of-n sampling or PPO.
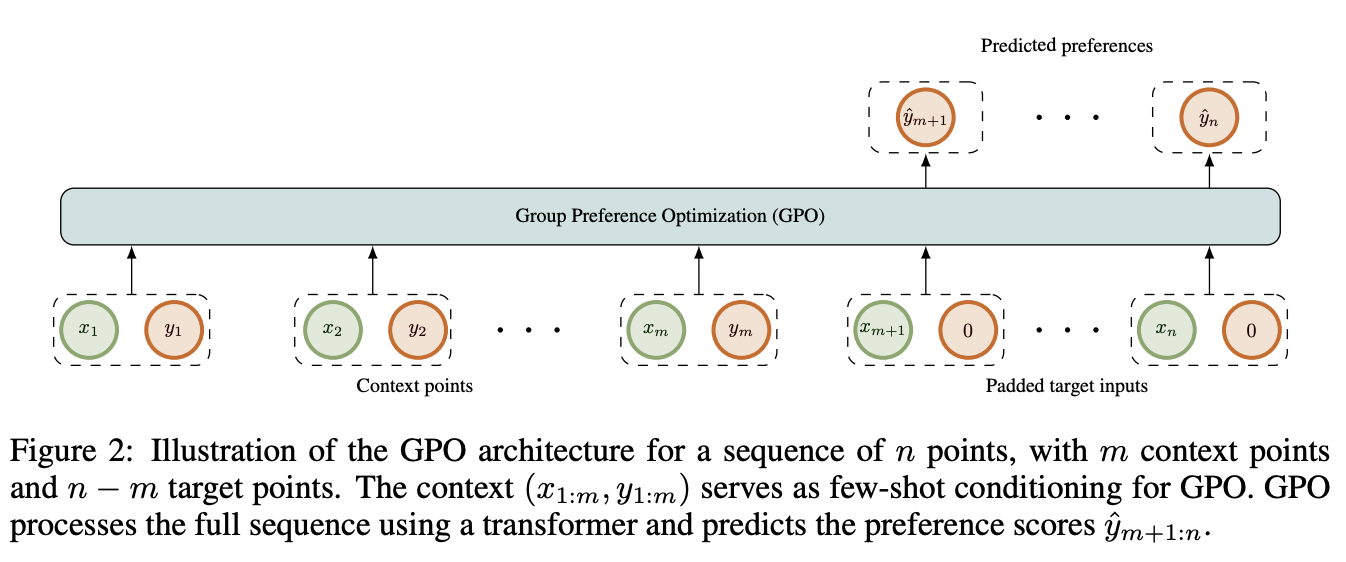
GPO parameterizes a novel transformer module which in-context learns to predict group preference scores for new LLM outputs given a few examples of LLM outputs and ground-truth preference scores from that group.

Results
Adapt to Group Preferences
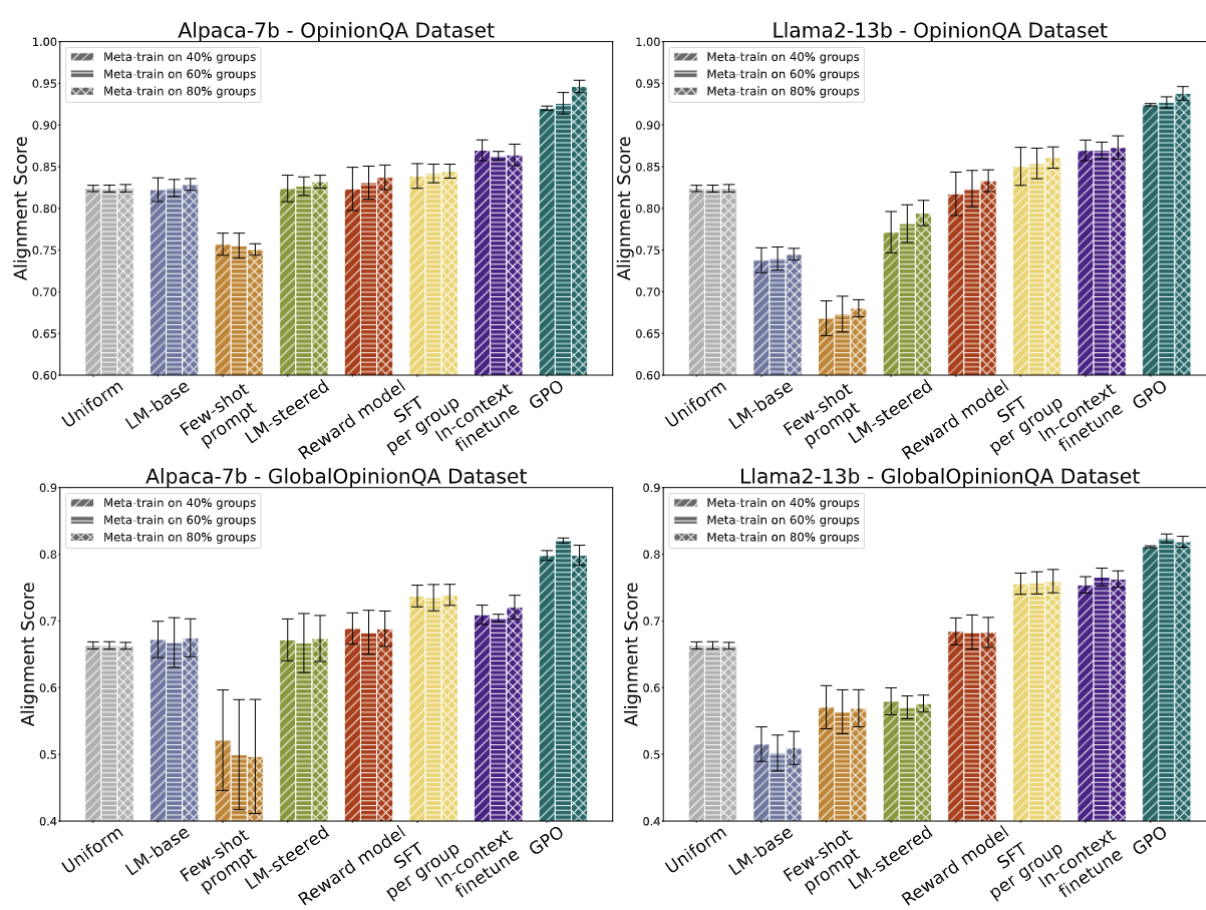
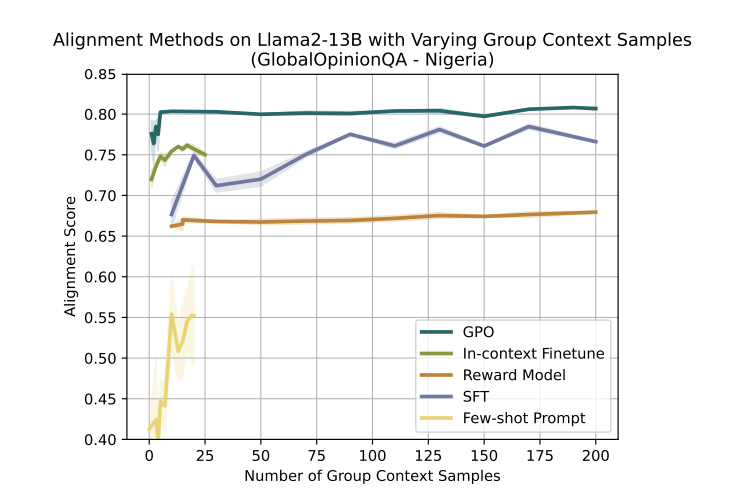
GPO-aligned LLM outputs exhibit higher alignment scores compared with common baseline methods for multiple popular open-source models across varying parameter and pretraining dataset size scales, and opinion datasets.
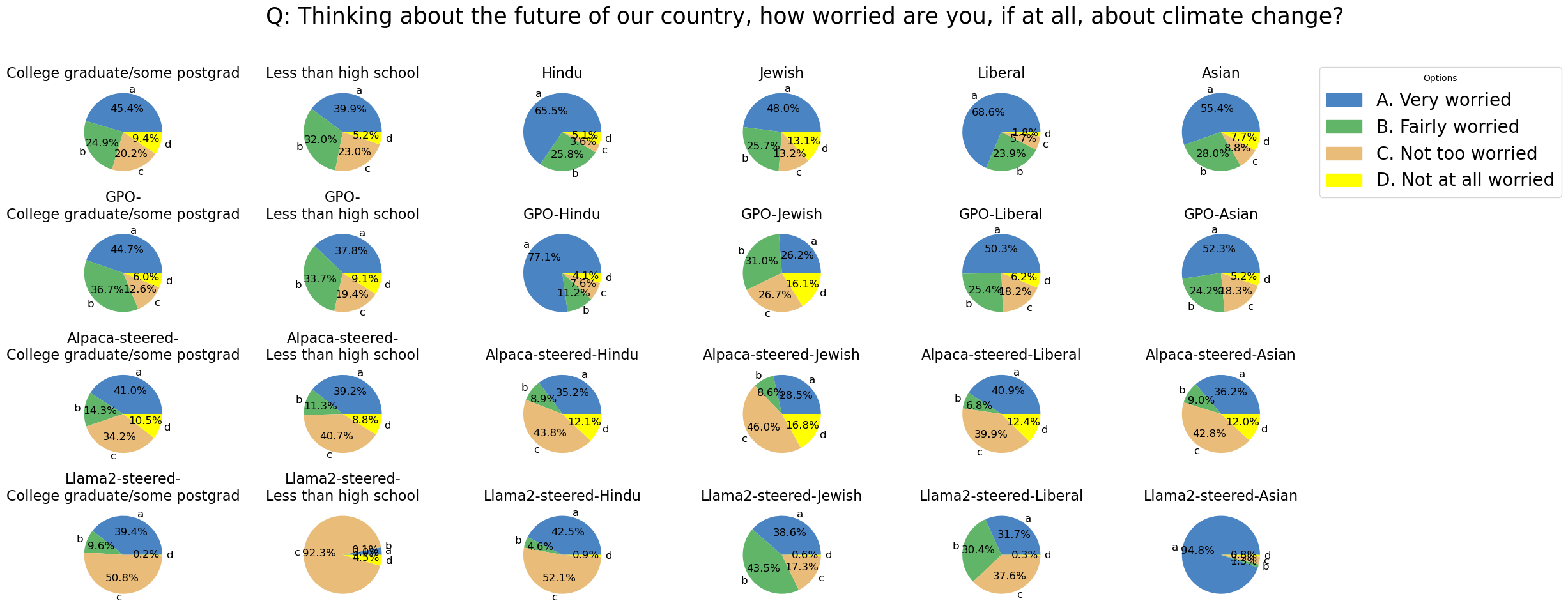
Qualitatively, we find that GPO-aligned LLM output distributions are significantly more similar to group ground truth distributions than baseline methods.
In the qualitative example below, the first row depicts the ground truth group opinion distribution. With limited context samples, GPO successfully adapts to match the opinion distributions of different groups. For instance, it increases preference for option A when adapted to the group Hindus, whereas other steered LMs do not exhibit correct distribution changes. In particular, Llama2-13b-steered seems biased towards a specific option, overemphasizing it instead of providing an accurate reflection of the targeted group's distribution.
In contrast, for demographics like College graduate/some postgrad that have a balanced opinion distribution, GPO preserves this balance effectively. This underlines GPO's ability not just to align with broad dataset group preferences, but also to fine-tune its alignment to specific groups with limited context.
Scalability with Increasing Context Samples. GPO is also significantly more sample efficient than baseline methods, achieving higher alignment scores while using fewer examples.
Adapt to Individual Preferences
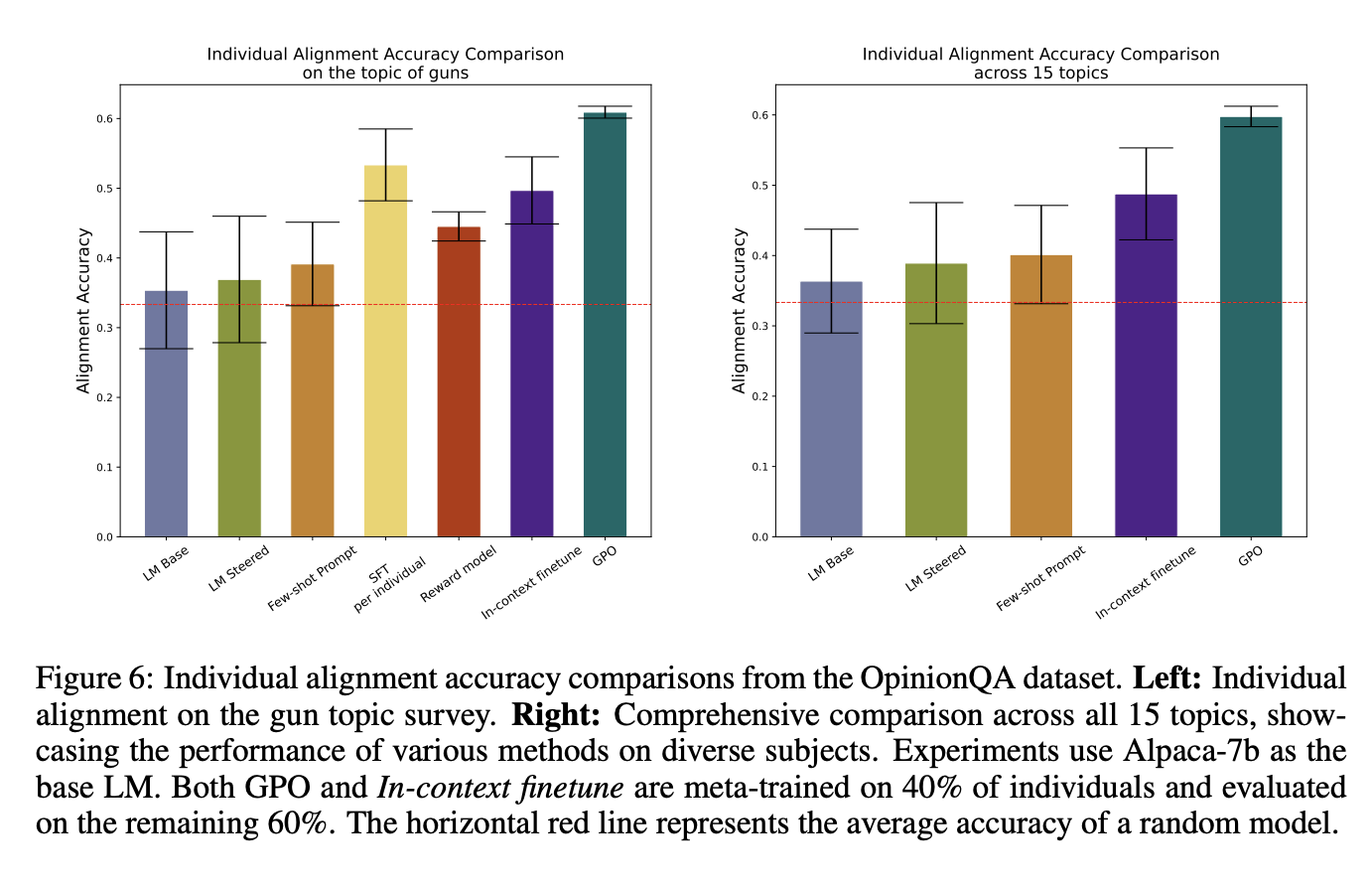
We also show that GPO is also able to adapt to a single individual’s preferences, a setting where there is often much higher variance between preference datasets than the group preference alignment setting.
Discussion and Future Work
GPO provides a framework for few-shot alligning LLMs to group preferences. GPO significantly outperforms prior methods as measured by alignment score for group preference alignment while requiring no gradient updates to the base LLM. We find that GPO is also more sample efficient, improving alignment score significantly more than baseline methods while using fewer samples, and is effective across multiple popular open-source LLMs of various parameter and pre-training dataset scales. Future work should explore adapting GPO with other datasets (especially non-mulitiple choice format), the impact of aligning to group preferences on alignment for other values including harmlessness or helpfulness, and using pre-training model initializations for the GPO module